Getting Started¶
The pan configuration language allows system administrators to define simultaneously a site configuration and a schema for validation. As a core component of the Quattor fabric management toolkit, the pan compiler translates this high-level site configuration to a machine-readable representation, which other tools can then use to enact the desired configuration changes.
Configuration Language¶
The pan language was designed to have a simple, human-friendly syntax. In addition, it allows more rigorous validation via its flexible data typing features when compared to, for instance, XML and XMLSchema.
The name “compiler” is actually a misnomer, as the pan compiler does much more than a simple compilation. The processing progresses through five stages:
- compilation
- Compile each individual template (file written in the pan configuration language) into a binary format.
- execution
- The statements the templates are executed to generate a partial tree of configuration information. The generated tree contains all configuration information directly specified by the system administrator.
- insertion of defaults
- A pass is made through the tree of configuration information during which any default values are inserted for missing elements. The tree of configuration information is complete after this stage.
- validation
- The configuration information is frozen and all standard and user-specified validation is done. Any invalid values or conditions will cause the processing to abort.
- serialization
- Once the information is complete and valid, it is serialized to a file. Usually, this file is in an XML format, but other representations are available as well.
The pan compiler runs through these stages for each “object” template. Usually there is one object template for each physical machine; although with the rise of virtualization, it may be one per logical machine.
Benefits¶
Using the pan language and compiler has the following benefits:
- Declarative language allows easier merging of configurations from different administrators.
- Encourages organization of configuration by service and function to allow sharing of configurations between machines and sites.
- Provides simple syntax for definition of configuration information and validation.
- Ensures a high-level of validation before configurations are deployed, avoiding interruptions in services and wasted time from recovery.
The language and compiler are intended to be used with other tools that manage the full set of configuration files and that can affect the changes necessary to arrive at the desired configuration. The Quattor toolkit provides such tools, although the compiler can be easily used in conjunction with others.
Download and Installation¶
The pan compiler can be invoked via the Unix (Linux) command line, ant, or maven. The easiest for the simple examples in this book is the command line interface. (See :ref:`running_panc`for installation instructions for all the execution methods.) Locate and download the latest version of the pan tarball and untar this into a convenient directory. You can find the packaged versions of the compiler in the releases area of the GitHub repository.
The pan compiler requires a Java Runtime Environment (JRE) or Java Development Kit (JDK) 1.6 or later. If you will just be running a binary version of the pan compiler, the JRE is sufficient; compiling the sources will require the JDK. Use a complete, certified version of the Java Virtual Machine.
Warning
The GNU Java Compiler (GJC) distributed with many Linux-based operating systems is not a certified version of the Java Virtual Machine. The pan compiler will not run correctly with it.
To use the compiler from the command line, you must make it accessible from the path.
$ export PANC_HOME=/panc/location
$ export PATH=$PANC_HOME/bin:$PATH
The above will work for Bourne shells on *nix-like operating systems; adjust the command for the operating system and shell that you use. Change the value of PANC_HOME to the directory where the pan compiler was unpacked.
Validating the Installation¶
Once you have installed the compiler, make sure that it is working correctly by using the command:
$ panc --help
This gives a complete list of all of the available options. If the command fails, review the installation instructions.
Invoking the Pan Compiler¶
Now create a file (called a “template”) named hello_world.pan that contains the following:
object template hello_world;
'/message' = 'Hello World!';
Compile this template into the default XML representation and look at the output.
$ panc hello_world.pan
$ cat hello_world.xml
<?xml version="1.0" encoding="UTF-8"?>
<nlist format="pan" name="profile">
<string name="message">Hello World!</string>
</nlist>
The output should look similar to what is shown above. As you can see the generated information has a simple structure: a top-level element of type nlist, named “profile” with a single string child, named “message”. The value of the “message” is “Hello World!”. If the output format is not specified, the default is the “pan” XML style shown above, in which the element names are the pan primitive types and the name attribute corresponds to the name of the field in the pan template.
The pan compiler can generate output in three additional formats: json, text, and dot. The following shows the output for the json format that was written to the hello_world.json file.
$ panc --formats json hello_world.pan
$ cat hello_world.json
{
"message": "Hello World!"
}
In this book, the most convenient representation is the text format. This provides a clean representation of the configuration tree in plain text.
$ panc --formats text hello_world.pan
$ cat hello_world.txt
+-profile
$ message : (string) 'hello'
The output file is named hello_world.txt. It provides the same information as the other formats, but is easier to read.
The last style is the “dot” format.
$ panc --formats dot hello_world.pan
$ cat hello_world.dot
digraph "profile" {
bgcolor = beige
node [ color = black, shape = box, fontname=Helvetica ]
edge [ color = black ]
"/profile" [ label = "profile" ]
"/profile/message" [ label = "message\n'Hello World!'" ]
"/profile" -> "/profile/message"
}
Although the text is not very enlightening by itself, it can be used by Graphviz to generate a graph of the configuration. Processing the above file with Graphviz produces the image shown in the Graph of hello_world.pan configuration.
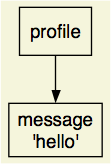
Graph of hello_world.pan configuration
A Whirlwind Tour¶
This tour will highlight the major features of the pan language by showing how the configuration for a batch system for asynchronous handling of jobs could be described with the pan language. The fictitious, simplified batch system used here gives you the flavor of the development process and common pan features. The description of a real batch system would contain significantly more parameters and services.
Batch System Description¶
A batch system provides a set of resources for asynchronous execution of jobs (scripts) submitted by users. The batch system (or cluster) consists of:
- Server (or head node)
- A machine containing a service for accepting job requests from users and a scheduler for dispatching those jobs to available workers.
- Workers
- Machines that accept jobs from the server, execute them, and then return the results to the server.
Users send a script containing the job description to the server. The server then queues the request for later execution. The scheduler periodically checks the queued jobs and resources, sending a queued job for execution on a worker if one is available. The worker executes the job it has been given and keeps the server informed about the state of the job. At the end of the job, results are returned to the server. The user can interact with the server to determine the status of jobs and to retrieve the output of completed jobs.
For our simplified batch system, we want to create a set of parameters that describe the configuration. For many real services, the configuration schema used in pan will closely mirror the configuration file(s) of the service. In our case we will create a configuration schema based on the above description.
The server controls a set of workers and manages jobs via a set of queues. Each queue is named, has a CPU limit, and can be enabled or disabled. Each node also has a name, participates in one or more queues, and has a set of capabilities (e.g. a particular software license is available, has a fast network connection, etc.).
The worker needs to know with which server to communicate. Each worker will also have a flag to indicate if the worker is enabled or disabled.
Naive Configuration¶
Given the previous description, a pan language configuration for both the batch server and one batch worker can easily be created. We must create an object template for each machine in order to have the machine descriptions created during the compilation. Create the file server.example.org.pan with the following contents:
object template server.example.org;
'/batch/server/nodes/worker01.example.org/queues'
= list('default');
'/batch/server/nodes/worker01.example.org/capabilities'
= list('sw-license', 'fast-network');
'/batch/server/queues/default/maxCpuHours' = 1;
'/batch/server/queues/default/enabled' = true;
It is customary to use the machine name as the object template name. For this server, there is one worker node named ‘worker01.example.org’ and one queue named ‘default’. The worker node participates in the ‘default’ queue and has a couple of capabilities. The ‘default’ queue has a CPU limit of 1 hour.
Create the file worker01.example.org.pan for the worker:
object template worker01.example.org;
'/batch/worker/server' = 'server.example.org';
'/batch/worker/enabled' = true;
This is part of the cluster controlled by the server ‘server.example.org’ and is enabled.
These templates can be compiled with the following command:
$ panc --formats text *.pan
which then produces the files server.example.org.txt and worker01.example.org.txt:
+-profile
+-batch
+-server
+-nodes
+-worker01.example.org
+-capabilities
$ 0 : (string) 'sw-license'
$ 1 : (string) 'fast-network'
+-queues
$ 0 : (string) 'default'
+-queues
+-default
$ maxCpuHours : (long) '1'
+-profile
+-batch
+-worker
$ enabled : (boolean) 'true'
$ server : (string) 'server.example.org'
These generated files (or more likely their equivalents in XML) can then be used by tools to actually configure the machines and batch services appropriately.
Using Namespaces and Includes¶
The naive configuration shown in the previous section has a couple of problems. First, it will become tedious to maintain, especially if individual machines contain a mix of different services. Second, similar configurations would be duplicated between object templates, increasing the likelihood of errors. These problems can be eliminated by refactoring the configuration into separate templates and by organizing those templates into reasonable namespaces.
As a first step in reorganizing the configuration, we pull out the batch server and worker configurations into separate ordinary templates. These configurations are put into services/batch-server.pan and services/batch-worker.pan, respectively.
template services/batch-server;
'/batch/server/nodes/worker01.example.org/queues'
= list('default');
'/batch/server/nodes/worker01.example.org/capabilities'
= list('sw-license', 'fast-network');
'/batch/server/queues/default/maxCpuHours' = 1;
'/batch/server/queues/default/enabled' = true;
template services/batch-worker;
'/batch/worker/server' = 'server.example.org';
'/batch/worker/enabled' = true;
Note that these files are not object templates (i.e. there is no object modifier) and will not produce any output files themselves. Note also that they are namespaced; the relative directory of the template must match the path hierarchy in the file system. In this particular case, these both must appear in a services subdirectory.
Object templates can also be namespaced; here we will put them into a profiles subdirectory. These object templates can then include configuration in other (non-object) templates. The contents of these profiles becomes:
object template profiles/server.example.org;
include 'services/batch-server';
object template profiles/worker01.example.org;
include 'services/batch-worker';
Organizing the service configurations in this way makes it easy to include multiple services in a particular object template. If reasonable names are chosen, then the object template becomes self-documenting, listing the services included on the machine.
The command to compile these object templates is slightly different:
$ panc --formats text profiles/*.pan
The output files by default will be placed next to the object template, so in this case they will be in the profiles subdirectory. You can verify that the reorganized configuration produces exactly the same configuration as the first example.
Simple Typing¶
Although the configuration is completely specified in the previous examples, it does not protect you from inappropriate values, for instance, specifying ‘ON’ for the boolean worker’s enabled parameter or a negative number for the maxCpuHours parameter of a queue. The pan language has a number of primitive types, collections, and mechanisms for user-defined types.
Create a file named services/batch-types.pan with the following content:
declaration template services/batch-types;
type batch_capabilities = string[];
type batch_queue_list = string[1..];
type batch_node = {
'queues' : batch_queue_list
'capabilities' ? batch_capabilities
};
type batch_queue = {
'maxCpuHours' : long(0..)
'enabled' : boolean
};
type batch_server = {
'nodes' : batch_node{}
'queues' : batch_queue{}
};
type batch_worker = {
'server' : string
'enabled' : boolean
};
The batch_worker type defines a record (dict or hash with named children) for the worker configuration. The ‘enabled’ flag is defined to be a boolean value. The ‘server’ is defined to be a string. For a real configuration, the server would likely be define to be a hostname or IP address with appropriate constraints.
The batch_server type also defines a record with nodes and queues children. These are both defined to be dicts where the keys are the worker host name or the queue name, respectively. The notation mytype{} defines an dict.
Type batch_queue type defines a record with the characteristics of a queue. Each queue can be enabled or disabled. The maxCpuHours is required to be a non-negative long value. The range specification (0..) limits the allowed values. Range limits like this apply to the numeric value for long and double types; it applies to the length for strings.
Type batch_node again defines a record for a single node. The node description contains a list of queues and a list of capabilities. In this case, the record specifier uses a question mark (‘?’) indicating that the field is optional; if the record specifier uses a colon (‘:’) then the field is required.
Type batch_queue_list is an alias for a list of strings, but also contains a range limitation [1..]. This range limitation means that the list must contain at least one element.
Type batch_capabilities is just an alias for a list of strings. It is a convenience type used to make the field description clearer.
The template declaration uses the declaration modifier. This means that the template will only be executed once during the build of a particular machine profile. It also limits the content of the template to variable, function, and type definitions.
A complete set of types is now available for the batch configuration, but at this point, none of these types have been attached to a part of the configuration. The bind statement associates a particular type to a path. Note that a single path can have multiple type declarations associated with it. For the batch configuration, the services/batch-server.pan and services/batch-worker.pan have had a bind statement added.
template services/batch-server;
include 'services/batch-types';
bind '/batch/server' = batch_server;
'/batch/server/nodes/worker01.example.org/queues'
= list('default');
'/batch/server/nodes/worker01.example.org/capabilities'
= list('sw-license', 'fast-network');
'/batch/server/queues/default/maxCpuHours' = 1;
'/batch/server/queues/default/enabled' = true;
template services/batch-worker;
include 'services/batch-types';
bind '/batch/worker' = batch_worker;
'/batch/worker/server' = 'server.example.org';
'/batch/worker/enabled' = true;
Types have been bound to two paths with these bind statements. If any of the content does not conform to the specified types, then an error will occur during the compilation. Note that we have not limited the values for paths other than these two paths and their children. Configuration in other paths can be added without being subject to these type definitions. A global schema can be defined by binding a type definition to the root path ‘/’.
Default Values¶
Very often configuration parameters can have reasonable default values, avoiding the need to specify them explicitly within a machine profile. The pan type system allows default values to be defined and then inserted into a machine configuration when necessary. The following is a modified version of the batch-types.pan file with default values added.
declaration template services/batch-types;
type batch_capabilities = string[];
type batch_queue_list = string[1..];
type batch_node = {
'queues' : batch_queue_list = list('default')
'capabilities' ? batch_capabilities
};
type batch_queue = {
'maxCpuHours' : long(0..) = 1
'enabled' : boolean = true
};
type batch_server = {
'nodes' : batch_node{}
'queues' : batch_queue{} = dict('default', dict())
};
type batch_worker = {
'server' : string
'enabled' : boolean = true
};
If the queue list for a node is not specified, then assume that the node will participate in the ‘default’ queue. That is, the default value is a one-element list containing the string ‘default’.
Default to 1 CPU-hour for the queue execution limit.
By default, a queue will be enabled.
If no queues are specified, then provide an dict containing only a queue definition for the ‘default’ queue. Note that the actual queue parameters are provided by the type definition batch_queue.
By default, a worker will be enabled.
Using these default values, then simplifies the configuration templates services/batch-server.pan and services/batch-worker.pan.
template services/batch-server;
include 'services/batch-types';
bind '/batch/server' = batch_server;
'/batch/server/nodes/worker01.example.org/capabilities'
= list('sw-license', 'fast-network');
template services/batch-worker;
include 'services/batch-types';
bind '/batch/worker' = batch_worker;
'/batch/worker/server' = 'server.example.org';
Compiling these templates will result in exactly the same generated files as with the previous configuration in which the default values were explicitly specified in the configuration. To use a value other than the default, the path just needs to be assigned the desired value. The defaults mechanism will never replace a value which was explicitly specified in the configuration.
Cross-Element and Cross-Machine Validation¶
Much of the power of using the pan language comes from its ability to ensure the consistency between different elements within a machine profile and between configurations of different machine profiles. In our example we have two cases where these types of validations would be useful: 1) the list of queues for a node should only reference defined queues and 2) the worker list on the server and the defined workers should be consistent.
The file batch-types.pan will be expanded to include validation functions for these cases. Each validation function must return true if the value is valid. If the value is not valid, then the function can return false or throw an exception via the error function. The error function allows you to provide a descriptive error message for the user. The contents of the modified file are:
declaration template services/batch-types;
function valid_batch_queue_list = {
foreach (index; queue_name; ARGV[0]) {
if (!path_exists('/batch/server/queues/' + queue_name)) {
return(false);
};
};
true;
};
function valid_batch_node_dict = {
foreach (hostname; properties; ARGV[0]) {
path = 'profiles/' + hostname + ':/batch/worker';
if (!path_exists(path)) {
error(path + ' doesn''t exist');
return(false);
};
};
true;
};
function server_exists = {
return(path_exists('profiles/' + ARGV[0] + ':/batch/server'));
};
function server_knows_about_me = {
regex = '^profiles/(.*)$';
if (match(OBJECT, regex)) {
parts = matches(OBJECT, regex);
path = 'profiles/' + ARGV[0] +
':/batch/server/nodes/' + parts[1];
if (!path_exists(path)) {
error(path + ' doesn''t exist');
};
} else {
error(OBJECT + ' doesn''t match ' + regex);
};
true;
};
function valid_server = {
(server_exists(ARGV[0]) && server_knows_about_me(ARGV[0]));
};
type batch_capabilities = string[];
type batch_queue_list = string[1..];
type batch_node = {
'queues' : batch_queue_list = list('default')
with valid_batch_queue_list(SELF)
'capabilities' ? batch_capabilities
};
type batch_queue = {
'maxCpuHours' : long(0..) = 1
'enabled' : boolean = true
};
type batch_server = {
'nodes' : batch_node{} with valid_batch_node_dict(SELF)
'queues' : batch_queue{} = dict('default', dict())
};
type batch_worker = {
'server' : string with valid_server(SELF)
'enabled' : boolean = true
};
The argument to this function is the batch queue list for a node. The function loops over the queue names and ensures that the associated path in the configuration exists. For example for the ‘default’ queue, the path ‘/batch/server/queues/default’ must exist.
The argument to this function is the dict of worker nodes. The function loops over the worker node entries and constructs a path using the worker node name. For example for the worker node ‘worker01.example.org’, it will construct the path ‘worker01.example.org:/batch/worker’. This is an external path that references another machine profile. In this case, the server profile ‘server.example.org’ will reference all of the worker profiles, e.g. ‘worker01.example.org’. If the node is configured as a worker, the path ‘/batch/worker’ will exist on the node.
The argument to this function is the name of the server as configured on a worker node. Similar to the previous function, this constructs a path on the referenced server and verifies that it exists. In this example, each worker will verify that the path ‘server.example.org:/batch/server’ exists.
The argument to this function is also the name of the server as configured on a worker node. This function will extract the list of workers in the server configuration and ensure that the worker’s name appears. This uses a regular expression to extract the machine name from the OBJECT variable, which contains the name of the object template being processed. The constructed path will exist if the server configuration contains the named worker node.
The argument to this function is the name of the server. It is a convenience function that combines the previous two functions.
These functions are tied to a type definition using a with clause. The with clause will execute the given code block for the given type after the profile has been fully constructed. Usually, the code block will reference the special variable SELF, which contains the value associated with the given type. Although any block of code can be used in the type definition, it is best practice to define a validation function with the code and reference that validation function. This makes the type definition easier to read. The with clauses for the cross-element and cross-machine validation are:
Run the valid_batch_queue_list function for all of the node queue lists.
Run the valid_batch_node_dict function for the server’s node dict.
Run the valid_server function for the worker node’s configured server.
This type of validation ensures internal and external consistency of machine configurations and can significantly enhance confidence in the defined configurations. Note that the cross-machine validation will work even with circular dependencies, allowing server and client validation for services.
Path Prefixes¶
Although in this particular example there is a limited number of parameters set, most real examples involve a large number of parameters and repetitive specifications of similar absolute paths. The prefix pseudo-statement is a convenience for reducing duplication in path specifications. The path provided in the prefix statement will be applied to any relative paths found in a template after the prefix statement.
As an example, we take the batch server configuration, adding a second worker node.
template services/batch-server;
include 'services/batch-types';
bind '/batch/server' = batch_server;
prefix '/batch/server/nodes';
'worker01.example.org/capabilities'
= list('sw-license', 'fast-network');
'worker02.example.org/capabilities' = list();
In this case, this saves us from having to duplicate the prefix ‘/batch/server/nodes’ for each worker node. Note that the prefix is expanded when the template is compiled and does not affect any included templates. Although multiple prefix statements can be used in a template, it is best practice to use only one near the beginning of the template.
Core Syntax¶
As you will have seen in the whirlwind tour, a complete site or service configuration consists of a set of files called “templates”. These files are usually managed via a versioning system to track changes and to permit reverting to an earlier state. The top-level syntax of the templates is especially simple: a template declaration followed by a list of statements that are executed in sequence. The compiler will serialize a machine profile, usually in XML format, for each “object” template it encounters.
Templates¶
Syntax¶
A machine configuration is defined by a set of files, called templates, written in the pan configuration language. These templates define simultaneously the configuration parameters, the configuration schema, and validation functions. Each template is named and is contained in a file having the same name.
Warning
All pan source files, templates as well as included files, must be encoded in UTF-8. No other character encodings are supported.
The syntax of a template file is simple:
[ modifier ] template template-name ;
[ statement ... ]
where the optional modifier is either object, structure, unique, or declaration. There are five different types of templates that are identified by the template modifier; the four listed above and an “ordinary” template that has no modifier.
A template name is a series of substrings separated by slashes. Each substring may consist of letters, digits, underscores, hyphens, periods, and pluses. The substrings may not be empty or begin with a period; the template name may not begin or end with a slash.
Each template must reside in a separate file with the name .pan with any terms separated with slashes corresponding to subdirectories. For example, a template with the name “service/batch/worker-23” must have a file name of worker-23.pan and reside in a subdirectory service/batch/.
Warning
The older file extension “tpl” is also accepted by the pan compiler, but is deprecated. Support for this older prefix will disappear in the next major release. Currently, if files with both extensions exist for a given template, then the file with the “pan” extension will be used by the compiler.
Types of Templates¶
Object Templates¶
An object template is declared via the object modifier. Each object template is associated with a machine profile and the pan compiler will, by default, generate an XML profile for each processed object template. An object template may contain any of the pan statements. Statements that operate on paths may contain only absolute paths.
Object template names may be namespaced, allowing organization of object templates in directory structures as is done for other templates. For the automatic loading mechanism to find object templates, the root directory containing them must be specified explicitly in the load path (either on the command line or via the LOADPATH variable).
Ordinary Templates¶
An ordinary template uses no template modifier in the declaration. These templates may contain any pan statement, but statements must operate only on absolute paths.
Unique Templates¶
A template defined with the unique modifier behaves like an ordinary template except that it will only be included once for each processed object template. It has the same restrictions as an ordinary template. It will be executed when the first include statement referencing the template is encountered.
Declaration Templates¶
A template declared with a declaration modifier is a declaration template. These templates may contain only those pan statements that do not modify the machine profile. That is, they may contain only type, bind, variable, and function statements. A declaration template will only be executed once for each processed object template no matter how many times it is included. It will be executed when the first include statement referencing the template is encountered.
Structure Templates¶
A template declared with the structure modifier may only contain include statements and assignment statements that operate on relative paths. The include statements may only reference other structure templates. Structure templates are an alternative for creating dicts and are used via the create function.
Comments¶
These files may contain comments that start with the hash sign (‘#’) and terminate with the next new line or end of file. Comments may occur anywhere in the file except in the middle of strings, where they will be taken to be part of the string itself.
Whitespace in the template files is ignored except when it is used to separate language tokens.
Statements¶
Assignment¶
Assignment statements are used to modify a part of the configuration tree by replacing the subtree identified by its path by the result of the execution a DML block. This result can be a single property or a resource holding any number of elements. The unconditional assignment is:
[ final ] path = dml;
where the path is represented by a string literal. Single-quoted strings are slightly more efficient, but double-quoted strings work as well.
The assignment will create parents of the value that do not already exist.
If a value already exists, the pan compiler will verify that the new value has a compatible type. If not, it will terminate the processing with an error.
If the final modifier is used, then the path and any children of that path may not be subsequently modified. Attempts to do so will result in a fatal error.
A conditional form of the assignment statement also exists:
[ final ] path ?= dml;
where the path is again represented by a string literal. The conditional form (?=) will only execute the DML block and assign a value if the named path does not exist or contains the undef value.
Prefix¶
The prefix (pseudo-)statement provides an absolute path used to resolve relative paths in assignment statements that occur afterwards in the template. It has the form:
prefix '/some/absolute/path';
The path must be an absolute path or an empty string. If the empty string is given, no prefix is used for subsequent assignment statements with relative paths. The prefix statement can be used multiple times within a given template.
This statement is evaluated at compile time and only affects assignment statements in the same file as the definition.
Include¶
The include statement acts as if the contents of the named template were included literally at the point the include statement is executed.
include dml;
The DML block must evaluate to a string, undef, or null. If the result is undef or null, the include statement does nothing; if the result is a string, the named template is loaded and executed. Any other type will generate an error.
Ordinary templates may be included multiple times. Templates marked as declaration or unique templates will be only included once where first encountered. Includes which create cyclic dependencies are not permitted and will generate a fatal error.
There are some restrictions on what types of templates can be included. Object templates cannot be included. Structure templates can only include and be included by other structure templates. Declaration templates can only include other declaration templates. All other combinations are allowed.
Variable Definition¶
Global variables can be defined via a variable statement. These may be referenced from any DML block after being defined. They may not be modified from a DML block; they can only be modified from a variable statement. Like the assignment statement there are conditional and unconditional forms:
[ final ] variable identifier ?= dml;
[ final ] variable identifier = dml;
For the conditional form, the DML block will only be evaluated and the assignment done if the variable does not exist or has the undef value.
If the final modifier is used, then the variable may not be subsequently modified. Attempts to do so will result in a fatal error.
Pan provides several automatic global variables: OBJECT, SELF, FUNCTION, TEMPLATE, and LOADPATH. OBJECT contains the name of the object template being evaluated; it is a final variable. SELF is the current value of a path referred to in an assignment or variable statement. The SELF reference cannot be modified, but children of SELF may be. FUNCTION contains the name of the current function, if it exists. FUNCTION is a final variable. TEMPLATE contains the name of the template that invoked the current DML block; it is a final variable. LOADPATH can be used to modify the load path used to locate template for the include statement.
Any valid identifier may be used to name a global variable.
Caution
Global and local variables share a common namespace. Best practice dictates that global variables have names with all uppercase letters (e.g. MY_GLOBAL_VAR) and local variables have names with all lowercase letters (e.g. my_local_var). This avoids conflicts and unexpected errors when sharing configurations.
Function Definition¶
Functions can be defined by the user. These are arbitrary DML blocks bound to an identifier. Once defined, functions can be called from any subsequent DML block. Functions may only be defined once; attempts to redefine an existing function will cause the compilation to abort. The function definition syntax is:
function identifier = dml;
See the Function section for more information on user-defined functions and a list of built-in functions.
Note that the compiler keeps distinct function and type namespaces. One can define a function and type with the same names.
Type Definition¶
Type definitions are critical for the validation of the generated machine profiles. Types can be built up from the primitive pan types and arbitrary validation functions. New types can be defined with:
type identifier = type-spec;
A type may be defined only once; attempts to redefine an existing type will cause the compilation to abort. Types referenced in the type-spec must already be defined. See the Type section for more details on the syntax of the type specification.
Note that the compiler keeps distinct function and type namespaces. One can define a function and type with the same name.
Validation¶
The bind statement binds a type definition to a path. Multiple types may be bound to a single path. During the validation phase, the value corresponding to the named path will be checked against the bound types.
bind path = type-spec;
See the Type section for a complete description of the type-spec syntax.
The valid statement binds a validation DML block to a path. It has the form:
valid path = DML;
This is a convenience statement and has exactly the same effect as the statement:
bind path = element with DML;
The pan compiler internally implements this statement as the bind statement above.
The path used in these statements can contain global variable references of the form ${vname}. This allows the binding between the validation code and a path to be determined when a profile is built. If the path references an undefined global variable, then will abort with an error. The build will also be aborted if the path is not valid after the values of the variables have been substituted. Below is an example of using global variable references:
variable MYFILE = 'test';
bind '/a/${MYFILE}' = type-spec;
As with any path element, the variable contents can be escaped if necessary by enclosing the variable reference into ‘{}’. For example:
variable MYFILE = '/tmp/test';
bind '/a/{${MYFILE}}' = type-spec;
See chapter on Validation for more details.
Data Types¶
The data typing system forms the foundation of the validation features of the pan language. All configuration elements are implicitly typed based on values assigned to them. Types, once inferred, are enforced by the compiler.
Type Hierarchy¶
There are four primitive, atomic types in the pan language: boolean, long, double, and string. Additionally, there are three string-like types: path, link, and regular expression. These appear in special constructs and have additional validity constraints associated with them. All of these atomic types are known as “properties”.
The language contains two types of collections: list and dict. The ‘list’ is an ordered list of elements, which uses the index (an integer) as the key. The named list (dict) associates a string key with a value; these are also known as hashes or associative lists. These collections are known as “resources”.
The complete type hierarchy is shown in the graph Pan language type hierarchy, including the two special types undef and null.
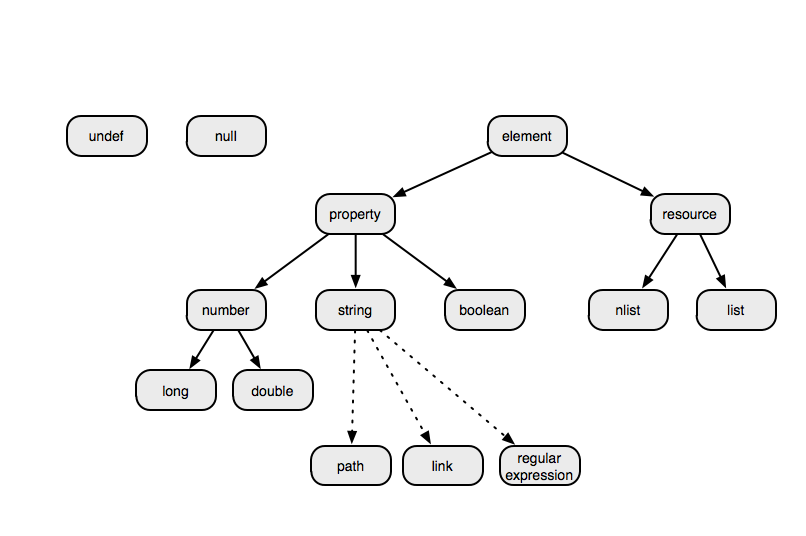
Pan language type hierarchy
Implicit Typing¶
If you worked through the exercises of the previous section, you will have discovered that although you have an intuitive idea of what type a particular path should contain (e.g. /hardware/cpu/number should be positive long), the pan compiler does not. Downstream tools to configure a machine will likely expect certain values to have certain types and will produce errors or erroneous configurations if the correct type is not used. One of the strengths of the pan language is to specify constraints on the values to detect problems before configurations are deployed to machines.
All of the elements in a configuration will have a concrete data type assigned to them. Usually this is inferred from the configuration itself. Once a concrete data type has been assigned to an element, the compiler will enforce the data type, disallowing replacement of a long value with a string, for instance. More detailed validation must be explicitly defined in the configuration (see the Validation chapter).
Properties and Primitive Types¶
Boolean Literals¶
There are exactly two possible boolean values: true and false. They must appear as an unquoted word and completely in lowercase.
Long Literals¶
Long literals may be given in decimal, hexadecimal, or octal format. A decimal literal is a sequence of digits starting with a number other than zero. A hexadecimal literal starts with the ‘0x’ or ‘0X’ and is followed by a sequence of hexadecimal digits. An octal literal starts with a zero is followed by a sequence of octal digits. Examples:
123 # decimal long literal
0755 # octal long literal
0xFF # hexadecimal long literal
Long literals are represented internally as an 8-byte signed number. Long values that cannot be represented in 8 bytes will cause a syntax error to be thrown.
Double Literals¶
Double literals represent a floating point number. A double literal must start with a digit and must contain either a decimal point or an exponent. Examples:
0.01
3.14159
1e-8
1.3E10
Note that ‘.2’ is not a valid double literal; this value must be written as ‘0.2’.
Double literals are represented internally as an 8-byte value. Double values that cannot be represented in 8 bytes will cause a syntax error to be thrown.
String Literals¶
The string literals can be expressed in three different forms. They can be of any length and can contain any character, including the NULL byte.
Single quoted strings are used to represent short and simple strings. They cannot span several lines and all the characters will appear verbatim in the string, except the doubled single quote which is used to represent a single quote inside the string. For instance:
’foo’
’it’’s a sentence’
’ˆ\d+\.\d+$’
This is the most efficient string representation and should be used when possible.
Double quoted strings are more flexible and use the backslash to represent escape sequences. For instance:
"foo"
"it’s a sentence"
"Java-style escapes: \t (tab) \r (carriage return) \n (newline)"
"Java-style escapes: \b (backspace) \f (form feed)"
"Hexadecimal escapes: \x3d (=) \x00 (NULL byte) \x0A (newline)"
"Miscellaneous escapes: \" (double quote) \\ (backslash)"
"this string spans two lines and\
does not contain a newline"
Invalid escape sequences will cause a syntax error to be thrown.
Multi-line strings can be represented using the ‘here-doc’ syntax, like in shell or Perl.
'/test' = 'foo' + <<EOT + 'bar';
this code will assign to the path '/test' the string
made of ‘foo’, plus this text including the final newline,
plus ‘bar’...
EOT
The contents of the ‘here-doc’ are treated as a single-quoted string. That is, no escape processing is done.
The easiest solution to put binary data inside pan code is to base64 encode it and put it inside “here-doc” strings like in the following example:
'/system/binary/stuff' = base64_decode(<<EOT);
H4sIAOwLyDwAA02PQQ7DMAgE731FX9BT1f8Q
Z52iYhthEiW/r2SitCdmxCK0E3W8no+36n2G
8UbOrYYWGROCgurBe4JeCexI2ahgWF5rulaL
tImkDxbucS0tcc3t5GXMAqeZnIYo+TvAmsL8
GGLobbUUX7pT+pxkXJc/5Bx5p0ki7Cgq5Kcc
GrCR8PzruUfP2xfJgVqHCgEAAA==
EOT
The base64_decode function is one of the built-in pan functions.
String-Like Types¶
Path¶
Pan paths are represented as string literals; either of the standard quoted forms for a string literal can be used to represent a path. There are three different types of paths: external, absolute, and relative.
An external path explicitly references an object template. The syntax for an external path is:
my/external/object:/some/absolute/path
where the substring before the colon is the template name and the substring after the colon is an absolute path. The leading slash of the absolute path is optional in an external path. This form will work for both namespaced and non-namespaced object templates.
An absolute path starts at the top of a configuration tree and identifies a node within the tree. All absolute paths start with a slash (“/”) and are followed by a series of terms that identify a specific child of each resource. A bare slash (“/”) refers to the full configuration tree. The allowed syntax for each term in the path is described below.
A relative path refers to a path relative to a structure template. Relative paths do not start with a slash, but otherwise are identical to the absolute paths.
Terms may consist of letters, digits, underscores, hyphens, and pluses. Terms beginning with a digit must be a valid long literal. Terms that contain other characters must be escaped, either by using the escape function within a DML block or by enclosing the term within braces for a path literal. For example, the following creates an absolute path with three terms:
/alpha/{a/b}/gamma
The second term is equivalent to escape(‘a/b’).
Link¶
A property can hold a reference to another element; this is known as a link. The value of the link is the absolute path of the referenced element. A property explicitly declared to be a link will be validated to ensure that 1) it represents a valid absolute path and 2) that the given path exists in the final configuration.
Regular Expression¶
Regular expressions are written as a standard pan string literals. The implementation exposes the Java regular expression syntax, which is largely compatible with the Perl regular expression syntax. Because certain characters have a special meaning in pan double quoted strings, characters like backslashes will need to be escaped; consequently, it is preferable to use single-quoted strings for regular expression literals.
When the compiler can infer that a string literal must be a regular expression, it will validate the regular expression at compile time, failing when an invalid regular expression is provided.
Resources¶
There are two types of resources supported by pan: list and dict. A list is an ordered list of elements with the indexing starting at zero. In the above example, there are two lists /hardware/disks/ide and /hardware/nic. The order of a list is significant and maintained in the serialized representation of the configuration. An dict (named list) associates a name with an element; these are also known as hashes or associative arrays. One dict in the above example is /hardware/cpu, which has arch, cores, model, number, and speed as children. Note that the order of an dict is not significant and that the order specified in the template file is not preserved in the serialized version of the configuration. Although the algorithm for ordering the children of an dict in the serialized file is not specified, the pan compiler guarantees a consistent ordering of the same children from one compilation to the next.
Within a given path, lists and dicts can be distinguished by the names of their children. Lists always have children whose names are valid long literals. In the following example, /mylist is a list with three children:
object template mylist;
'/mylist/0' = 'decimal index';
'/mylist/01' = 'octal index';
'/mylist/0x2' = 'hexadecimal index';
The indices can be specified in decimal, octal, or hexadecimal. The names of children in an dict must begin with a letter or underscore.
Special Types¶
The pan language contains two special types: undef and null.
The undef literal can be used to represent the undefined element, i.e. an element which is neither a property nor a resource. The undefined element cannot be written to a final machine profile and most built-in functions will report a fatal error when processing it. It can be used to mark an element that must be overwritten during the processing.
The null value deletes the path or global variable to which it is assigned. Most operations and functions will report an error if this value is processed directly.
Data Manipulation Language (DML)¶
Any non-trivial configuration will need to have some values that are calculated. The Data Manipulation Language (DML), a subset of the full pan configuration language, fulfills this role. This subset has the features of many imperative programming languages, but can only be used on the right-hand side of a statement, that is, to calculate a value.
DML Syntax¶
A DML block consists of one or more statements separated by semicolons. The block must be delimited by braces if there is more than one statement. The value of the block is the value of the last statement executed within the block. All DML statements return a value, even flow control statements like if and foreach.
Variables¶
To ease data handling, you can use local variables in any DML expression. They are scoped to the outermost enclosing DML expression. They do not need to be declared before they are used. The local variables are destroyed once the outermost enclosing DML block terminates.
As a first approximation, variables work the way you expect them to work. They can contain properties and resources and you can easily access resource children using square brackets:
# populate /table which is an dict
’/table/red’ = ’rouge’;
’/table/green’ = ’vert’;
’/test’ = {
x = list(’a’, ’b’, ’c’); # x is a list
y = value(’/table’); # y is a dict
z = x[1] + y[’red’]; # z is a string ('arouge')
length(z); # this will be 6
};
Local variables are subject to primitive type checking. So the primitive type of a local variable cannot be changed unless the variable is assigned to undef or null between the type-changing assignments.
Global variables (defined with the variable statement) can be read from the DML block. Global variables may not be modified from within the block; attempting to do so will abort the execution.
Caution
Global and local variables share the same namespace. Consequently, there may be unintended naming conflicts between them. The best practice to avoid this is to name all local variables with all lowercase letters (e.g. my_local_var) and all global variables with all uppercase letters (e.g. MY_GLOBAL_VAR).
Operators¶
The operators available in the pan Data Manipulation Language (DML) are very similar to those in the Java or c languages. The following tables summarize the DML operators. The valid primitive types for each operator are indicated. Those marked with “number” will take either long or double arguments. In the case of binary operators, the result will be promoted to a double if the operands are mixed.
| + | number | preserves sign of argument |
| - | number | changes sign of argument |
| ~ | long | bitwise not |
| ! | boolean | logical not |
Table: Unary DML Operators
| + | number | addition |
| + | string | string concatenation |
| - | number | subtraction |
| * | number | multiplication |
| / | number | division |
| % | long | modulus |
| & | long | bitwise and |
| | | long | bitwise or |
| ^ | long | bitwise exclusive or |
| && | boolean | logical and (short-circuit logic) |
| || | boolean | logical or (short-circuit logic) |
| == | number | equal |
| == | string | lexical equal |
| != | number | not equal |
| != | string | lexical not equal |
| > | number | greater than |
| > | string | lexical greater than |
| >= | number | greater than or equal |
| >= | string | lexical greater than or equal |
| < | number | less than |
| < | string | lexical less than |
| <= | number | less than or equal |
| <= | string | lexical less than or equal |
Table: Binary DML Operators
| || |
| && |
| | |
| ^ |
| & |
| ==, != |
| <, <=, >, >= |
| + (binary), - (binary) |
| *, /, % |
| + (unary), - (unary), !, ~ |
Table: Operator Precedence (lowest to highest)
Flow Control¶
DML contains four statements that permit non-linear execution of code within a DML block. The if statement allows conditional branches, the while statement allows looping over a DML block, the for statement allows the same, and the foreach statement allows iteration over an entire resource (list or dict).
Caution
These statements, like all DML statements, return a value. Be careful of this, because unexecuted blocks generally will return undef, which may lead to unexpected behavior.
Branching (if statement)¶
The if statement allows the conditional execution of a DML block. The statement may include an else clause that will be executed if the condition is false. The syntax is:
if ( condition-dml ) true-dml;
if ( condition-dml ) true-dml else false-dml;
where all of the blocks may either be a single DML statement or a multi-statement DML block.
The value returned by this statement is the value returned by the true-dml or false-dml block, whichever is actually executed. If the else clause is not present and the condition-dml is false, the if statement returns undef.
Looping (while and for statements)¶
Simple looping behavior is provided by the while statement. The syntax is:
while ( condition-dml ) body-dml;
The loop will continue until the condition-dml evaluates as false. The value of this statement is that returned by the body-dml block. If the body-dml block is never executed, then undef is returned.
The pan language also contains a for statement that in many cases provides a more concise syntax for many types of loops. The syntax is:
for (initialization-dml; condition-dml; increment-dml) body-dml;
The initialization-dml block will first be executed. Before each iteration the condition-dml block will be executed; the body-dml will only be executed (again) if the condition evaluates to true. After each iteration, the increment-dml block is executed. If the condition never evaluates to true, then the value of the statement will be that of the initialization-dml. All of the DML blocks must be present, but those not of interest can be defined as just undef.
Note that the compiler enforces an iteration limit to avoid infinite loops. Loops exceeding the iteration limit will cause the compiler to abort the execution. The value of this limit can be set via a compiler option.
Iteration (foreach statement)¶
The foreach statement allows iteration over all of the elements of a list or dict. The syntax is:
foreach (key; value; resource) body-dml;
This will cause the body-dml to be executed once for each element in resource (a list or dict). The local variables key and value (you can choose these names) will be set at each iteration to the key and value of the element. For a list, the key is the element’s index. The iteration will always occur in the natural order of the resource: ordinal order for lists and lexical order of the keys for dicts.
The value returned will be that of the last iteration of the body-dml. If the body-dml is never executed (for an empty list or dict), undef will be returned.
The foreach statement is not subject to the compiler’s iteration limit. By definition, the resource has a finite number of entries, so this safeguard is not needed.
This form of iteration should be used in preference to the first, next, and key functions whenever possible. It is more efficient than the functional forms and less prone to error.
Functions¶
The pan configuration has a rich set of built-in functions for manipulating elements and for debugging. In addition, user-defined functions can be specified, which are often used to make configurations more modular and maintainable.
Built-In Functions¶
Built-in functions are actually treated as operators within the DML language. Because of this, they are highly optimized and often process their arguments specially. In all cases, users should prefer built-in functions to user-defined functions when possible. The following tables describe all of the built-in functions; refer to the appendix to see the arguments and other detailed information about the functions.
| Name | Description |
|---|---|
| file_contents | Lookup the named file and provide the file’s contents as a string. |
| file_exists | Lookup the named file and return true if it exists; return false otherwise. |
| format | Generate a formatted string based on the formatting parameters and the values provided. |
| index | Return the index of a substring or -1 if the substring is not found. |
| length | Gives the length of a string. |
| match | Return a boolean indicating if a string matches the given regular expression. |
| matches | Return an array containing the matched string and matched groups for a given string and regular expression. |
| replace | Replace all occurrences of a substring within a given string. |
| splice | Remove a substring and optionally replace it with another. |
| split | Split a string based on a given regular expression and return an array of the results. |
| substitute | Substitute named values in a string template. |
| substr | Extract a substring from the given string. |
| to_lowercase | Change all of the characters in a string to lowercase (using the US locale). |
| to_uppercase | Change all of the characters in a string to uppercase (using the US locale). |
Table: String Manipulation Functions
| Name | Description |
|---|---|
| debug | Print a debugging message to the standard error stream. Returns the message or undef. |
| error | Print an error message to the standard error and terminate processing. |
| traceback | Print an error message to the standard error along with a traceback. Returns undef. |
| deprecated | Print a warning message to the standard error if required by the deprecation level in effect. Returns ``the message
|
Table: Debugging Functions
| Name | Description |
|---|---|
| base64_decode | Decode a string that is encoded using the Base64 standard. |
| base64_encode | Encode a string using the Base64 standard. |
| digest | Create message digest using specified algorithm. |
| escape | Escape characters within the string to ensure string is a valid dict key (path term). |
| unescape | Transform an escaped string into its original form. |
Table: Encoding and Decoding Functions
| Name | Description |
|---|---|
| append | Add a value to the end of a list. |
| create | Create an dict from the named structure template. |
| first | Initialize an iterator over a resource. Returns a boolean to indicate if more values exist in the resource. |
| dict | Create an dict from the given key/value pairs given as arguments. |
| key | Find the n’th key in an dict. |
| length | Get the number of elements in the given resource. |
| list | Create a list from the given arguments. |
| merge | Perge two resources into a single one. This function always creates a new resource and leaves the arguments untouched. |
| next | Extract the next value while iterating over a resource. Returns a boolean to indicate if more values exist in the resource. |
| prepend | Add a value to the beginning of a list. |
| splice | Remove a section of a list and optionally replace removed values with those in a given list. |
Table: Resource Manipulation Functions
| Name | Description |
|---|---|
| is_boolean | Check if the argument is a boolean value. If the argument is a simple variable reference and the referenced variable does not exist, the function will return false rather than raising an error. |
| is_defined | Check if the argument is a value other than null or undef. If the argument is a simple variable reference and the referenced variable does not exist, the function will return false rather than raising an error. |
| is_double | Check if the argument is a double value. If the argument is a simple variable reference and the referenced variable does not exist, the function will return false rather than raising an error. |
| is_list | Check if the argument is a list. If the argument is a simple variable reference and the referenced variable does not exist, the function will return false rather than raising an error. |
| is_long | Check if the argument is a long value. If the argument is a simple variable reference and the referenced variable does not exist, the function will return false rather than raising an error. |
| is_dict | Check if the argument is an dict. If the argument is a simple variable reference and the referenced variable does not exist, the function will return false rather than raising an error. |
| is_null | Check if the argument is a null. If the argument is a simple variable reference and the referenced variable does not exist, the function will return false rather than raising an error. |
| is_number | Check if the argument is either a long or double value. If the argument is a simple variable reference and the referenced variable does not exist, the function will return false rather than raising an error. |
| is_property | Check if the argument is a property (long, double, or string). If the argument is a simple variable reference and the referenced variable does not exist, the function will return false rather than raising an error. |
| is_resource | Check if the argument is a list or dict. If the argument is a simple variable reference and the referenced variable does not exist, the function will return false rather than raising an error. |
| is_string | Check if the argument is a string value. If the argument is a simple variable reference and the referenced variable does not exist, the function will return false rather than raising an error. |
Table: Type Checking Functions
| Name | Description |
|---|---|
| to_boolean | Convert the argument to a boolean. Any number other than 0 and 0.0 is true. The empty string and the string ‘false’ (ignoring case) return false. Any other string will return true. If the argument is a resource, an error will occur. |
| to_double | Convert the argument to a double value. Strings will be parsed to create a double value; any literal form of a double is valid. Boolean values will convert to 0.0 and 1.0 for false and true, respectively. Long values are converted to the corresponding double value. Double values are unchanged. |
| to_long | Convert the argument to a long value. Strings will be parsed to create a long value; any literal form of a long is valid (e.g. hex or octal literals). Boolean values will convert to 0 and 1 for false and true, respectively. Double values are rounded to the nearest long value. Long values are unchanged. An optional second argument can be provided that defines the radix to use. |
| to_string | Convert the argument to a string. The function will return a string representation for any argument, including list and dict. |
| ip4_to_long | Convert the argument, which must be a string representing an IPv4 address in dotted notation to a long. |
| long_to_ip4 | Convert the argument, a long into an IPv4 address in numbers-and-dots notation |
Table: Type Conversion Functions
| Name | Description |
|---|---|
| clone | Create a deep copy of the given value. |
| delete | Delete a local variable or child of a local variable. |
| exists | Return true if the given argument exists. The argument can either be a variable reference, path, or template name. |
| path_exists | Return true if the given path exists. The argument must be an absolute or external path. |
| if_exists | For a given template name, return the template name if it exists or undef if it does not. This can be used with the include statement for a conditional include. |
| return | Interrupt the normal flow of processing and return the given value as the result of the current frame (either a function call or the main DML block). |
| value | Retrieve the value associated with the given path. The path may either be an absolute or external path. |
Table: Miscellaneous Functions
User-Defined Functions¶
The pan language permits user-defined functions. These functions are essentially a DML block bound to an identifier. Only one DML block may be assigned to a given identifier. Attempts to redefine an existing function will cause the execution to be aborted. The syntax for defining a function is:
function = DML;
where identifier is a valid pan identifier and DML is the block to bind to it.
When the function is called, the DML will have the variables ARGC and ARGV defined. The variable ARGC contains the number of arguments passed to the function; ARGV is a list containing the values of the arguments.
Note that ARGV is a standard pan list. Consequently, passing null values (intended to delete elements) to functions can have non-obvious effects. For example, the call:
f(null);
will result is an empty ARGV list because the null value deletes the nonexistent element ARGV[0].
The pan language does not check the number or types of arguments automatically. The DML block that defines the function must make all of these checks explicitly and use the error function to emit an informative message in case of an error.
Recursive calls to a function are permitted. However, the call depth is limited (by an option when the compiler is invoked) to avoid infinite recursion. Typically, the maximum is a small number like 10. Recursion is expensive within the pan language and should be avoided if possible.
The following example defines a function that checks if the number of arguments is even and are all numbers:
function paired_numbers = {
if (ARGC%2 != 0) {
error('number of arguments must be even');
};
foreach (k, v, ARGV) {
if (! is_number(v)) {
error('non-numeric argument found');
};
};
'ok';
};
Validation¶
The greatest strength of the pan language is the ability to do detailed validation of configuration parameters, of correlated parameters within a machine profile, and of correlated parameters between machine profiles. Although the validation can make it difficult to get a particular machine profile to compile, the time spent getting a valid machine configuration before deployment more than makes up for the time wasted debugging a bad configuration that has been deployed.
Forcing Validation¶
Simple validation through the validation of primitive properties and simple resources has already been covered when discussing the pan type definition features. This chapter deals with more complicated scenarios.
The following statement will bind an existing type definition (either a built-in definition or a user-defined one) to a path in a machine configuration:
bind path = type-spec;
where path is a valid path name and type-spec is either a type specification or name of an existing type.
Full type specifications are of the form:
identifier = constant with validation-dml
where constant is a DML block that evaluates to a compile-time constant (the default value), and the validation-dml is a DML block that will be run to validate paths associated with this type. Both the default value and validation block are optional. The identifier can be any legal name with an optional array specifier and/or range afterwards. For example, an array of 5 elements is written int[5] or a string of length 5 to 10 characters string(5..10).
Implicit Typing¶
If you worked through the previous chapters, you will have discovered that although you have an intuitive idea of what type a particular path should contain (e.g. /hardware/cpu/number should be positive long), the pan compiler does not. The compiler will infer an element’s data type from the first value assigned to it. From then on it will enforce that type, raising an error if, for instance, a double is replaced by a string. If necessary, the implicit type can be removed from an element by assigning it to undef before changing the value.
Binding Primitive Types to Paths¶
Downstream machine configuration tools will likely expect parameters to have certain types, producing errors or erroneous configurations if the correct type is not used. One of the strengths of the pan language is to specify explicit constraints on the element to detect problems before configurations are deployed to machines.
At the most basic level, a system administrator can tell the pan compiler that a particular element must be a particular type. This is done with the bind statement. To tell the compiler that the path /hardware/cpu/number must be a long value, add the following statement to the nfsserver.example.org example.
bind '/hardware/cpu/number' = long;
This statement can appear anywhere in the file; all of the specified constraints will be verified after the complete configuration is built. Setting this path to a value that is not a long or not setting the value at all will cause the compilation to fail.
The above constraint only does part of the work though; the value could still be set to zero or a negative value without having the compiler complain. Pan also allows a range to be specified for primitive values. Changing the statement to the following:
bind '/hardware/cpu/number' = long(1..);
will require that the value be a positive long value. A valid range can have the minimum value, maximum value, or both specified. A range is always inclusive of the endpoint values. The endpoint values must be long literal values. A range specified as a single value indicates an exact match (e.g. 3 is short-hand for 3..3). A range can be applied to a long, double, or string type definition. For strings, the range is applied to the length of the string.
User-Defined Types¶
Users can create new types built up from the primitive types and with optional validation functions. The general format for creating a new type is:
type identifier = type-spec;
where the general form for a type specification type-spec is given above.
Probably the easiest way to understand the type definitions is by example. The following are “alias” types that associate a new name with an existing type, plus some restrictions.
type ulong1 = long with SELF >= 0;
type ulong2 = long(0..);
type port = long(0..65535);
type short_string = string(..255);
type small_even = long(-16..16) with SELF % 2 == 0;
Similarly one can create link types for elements in the machine configuration:
type mylink = long(0..)* with match(SELF, 'r$');
Values associated to this type must be a string ending with ‘r’; the value must be a valid path that references an unsigned long value.
Slightly more complex is to create uniform collections:
type long_list = long[10];
type matrix = long[3][4];
type double_dict = double{};
type small_even_dict = small_even{};
Here all of the elements of the collection have the same type. The last example shows that previously-defined, user types can be used as easily as the built-in primitive types.
A record is an dict that explicitly names and types its children. A record is by far, the most frequently encountered type definition. For example, the type definition:
type cpu = {
'vendor' : string
'model' : string
'speed' : double
'fpu' ? boolean
};
defines an dict with four children named ‘vendor’, ‘model’, etc. The first three fields use a colon (”:”) in the definition and are consequently required fields; the last uses a question mark (”?”) and is optional. As defined, no other children may appear in dicts of this type. However, one can make the record extensible with:
type cpu = extensible {
'vendor' : string
'model' : string
'speed' : double
'fpu' ? boolean
};
This will check the types of ‘vendor’, ‘model’, etc., but will also allow children of the dict with different unlisted names to appear. This provides some limited subclassing support. Each of the types for the children can be a full type specification and may contain default values and/or validation blocks. One can also attach default values or validation blocks to the record as a whole.
Default Values¶
Looking again at the nfsserver.example.org configuration, there are a couple of places where we could hope to use default values. The pxeboot and boot flags in the nic and disk type definitions could use default values. In both cases, at most one value will be set to true; all other values will be set to false. Another place one might want to use default values is in the cpu type; perhaps we would like to have number and cores both default to 1 if not specified.
Pan allows type definitions to contain default values. For example, to change the three type definitions mentioned above:
type cpu = {
'model' : string
'speed' : double(0..)
'arch' : string
'cores' : long(1..) = 1
'number' : long(1..) = 1
};
type nic = {
'mac' : string
'pxeboot' : boolean = false
};
type disk = {
'label' ? string
'capacity' : long(1..)
'boot' : boolean = false
};
With these definitions, the lines which set the pxeboot and boot flags to false can be removed from the configuration and the compiler will still produce the same result. The default value will only be used if the corresponding element does not exist or has the undef value after all of the statements for an object have been executed. Consequently, a value that has been explicitly defined will always be used in preference to the default. Although one can set a default value for an optional field in a record, it will have an effect only if the value was explicitly set to undef.
The default values must be a compile time constants.
Advanced Parameter Validation¶
Often there are cases where the legal values of a parameter cannot be expressed as a simple range. The pan language allows you to attach arbitrary validation code to a type definition. The code is attached to the type definition using the with keyword. Consider the following examples:
type even_positive_long = long(1..) with (SELF % 2 == 0);
type machine_state_enum = string
with match(SELF, 'open|closed|drain');
type ip = string with is_ipv4(SELF);
The validation code must return the boolean value true, if the associated value is correct. Returning any other value or raising an error with the error function will cause the build of the machine configuration to abort.
Simple constraints are often written directly with the type statement; more complicated validation usually calls a separate function. The third line in the example above calls the function is_ipv4, which was defined in the next section.
Validation Functions¶
To simplify type definitions, validation functions are often defined. These are user-defined functions defined using the standard function statement. They can be referenced within a type definition just as they would be in any DML block. However, validation functions must return a boolean value or raise an error with the error function. A validation function that returns a non-boolean value will abort the compilation. Similarly, a validation function that returns false will raise an error indicating that the value for the tested element is invalid.
A validation function that checks that a value is a valid IPv4 address could look like:
function is_ipv4 = {
terms = split('\.', ARGV[0]);
foreach (index; term; terms) {
i = to_long(term);
if (i < 0 || i > 255) {
return(false);
};
};
true;
};
A real version of this function would probably do a great deal more checking of the value and probably raise errors with more intuitive error messages.
Cross-Machine Validation¶
Another common situation is the need to validate machine configurations against each other. This often arises in client/server situations. For NFS, for instance, one would probably like to verify that a network share mounted on a client is actually exported by the server. The following example will do this:
# Determine that a given mounted network share is actually
# exported by the server.
function valid_export = {
info = ARGV[0];
myhost = info['host'];
mypath = info['path'];
exports_path = host + ':/software/components/nfs/exports';
found = false;
if (path_exists(exports_path)) {
exports = value(exports_path);
foreach (index; einfo; exports) {
if (einfo['authorized_host'] == myhost &&
einfo['path'] == mypath) {
found = true;
};
};
};
found;
};
# Defines path and authorized host for NFS server export.
type nfs_exports = {
'path' : string
'authorized_host' : string
};
# Type containing parameters to mount remote NFS volume.
type nfs_mounts = {
'host' : string
'path' : string
'mountpoint' : string
} with valid_export(SELF);
# Allows lists of NFS exports and NFS mounts (both optional).
type config_nfs = {
include component
'exports' ? nfs_exports[]
'mounts' ? nfs_mounts[]
};
To do this type of validation, the full external path must be constructed for the value function. This has the same disadvantage as above in that if the schema is changed the function definition needs to be altered accordingly. The above code also assumes that the machine profile names are equivalent to the hostname. If another convention is being used, then the hostname will have to be converted to the corresponding machine name.
It is worth noting that all of the validation is done after the machine configuration trees are built. This allows circular validation dependencies to be supported. That is, clients can check that they are properly included in the server configuration and the server can check that its clients are configured. A batch system is a typical example where this circular cross-validation is useful.
Schemas¶
The pan language allows complete configuration schema to be defined. Actually, you are capable of doing this already as defining a schema is nothing more than defining a type and binding that type to the root element. An example of this is:
object template schema_example;
include { 'type_definitions' };
type schema = {
'software' : software_type
'hardware' : hardware_type
'packages' : packages_type
};
bind '/' = schema;
# Actual definitions of parameters.
# ...
In this fictitious example, the concrete types would be defined in the included file and the template would actually define the configuration parameters.
Modular Configurations¶
Defining the configuration for a machine with many services, let alone a full site, quickly involves a large number of parameters. Often subsets of the configuration can be shared between services or machines. To minimize duplication and encourage sharing of configurations, the pan language has features to allow modularization of the configuration.
Include Statement¶
So far only the hardware configuration and schema for one machine has been defined with the nfsserver.example.org configuration. One could imagine just doing a cut and paste to create the other three machines in our scenario. While this will work, the global site configuration will quickly become unwieldy and error-prone. In particular the schema is something that should be shared between all or many machines on a site. Multiple copies means multiple copies to keep up-to-date and multiple chances to introduce errors.
To encourage reuse of the configuration and to reduce maintenance effort, pan allows one template to include another (with some limitations). For example, the above schema can be pulled into another template (named common/schema.tpl) and included in the main object template.
declaration template common/schema;
type location = extensible {
'rack' : string
'slot' : long(0..50)
};
type cpu = {
'model' : string
'speed' : double(0..)
'arch' : string
'cores' : long(1..)
'number' : long(1..)
};
type disk = {
'label' ? string
'capacity' : long(1..)
'boot' : boolean
};
type disks = {
'ide' ? disk[]
'scsi' ? disk{}
};
type nic = {
'mac' : string
'pxeboot' : boolean
};
type hardware = {
'location' : location
'ram' : long(0..)
'cpu' : cpu
'disks' : disks
'nic' : nic[]
};
type root = {
'hardware' : hardware
};
The main object template then becomes:
object template nfsserver.example.org;
include 'common/schema';
bind '/' = root;
'/hardware/location/rack' = 'IBM04';
'/hardware/location/slot' = 25;
'/hardware/ram' = 2048;
'/hardware/cpu/model' = 'Intel Xeon';
'/hardware/cpu/speed' = 2.5;
'/hardware/cpu/arch' = 'x86_64';
'/hardware/cpu/cores' = 4;
'/hardware/cpu/number' = 2;
'/hardware/disk/ide/0/capacity' = 64;
'/hardware/disk/ide/0/boot' = true;
'/hardware/disk/ide/0/label' = 'system';
'/hardware/disk/ide/1/capacity' = 1024;
'/hardware/disk/ide/1/boot' = false;
'/hardware/nic/0/mac' = '01:23:45:ab:cd:99';
'/hardware/nic/0/pxeboot' = false;
'/hardware/nic/1/mac' = '01:23:45:ab:cd:00';
'/hardware/nic/1/pxeboot' = true;
There are three important changes to point out.
First, there is a new pan statement in the nfsserver.example.org template to include the schema. The include statement takes the name of the template to include as a string; the braces are mandatory. If the template is not included directly on the command line, then the compiler will search the loadpath for the template. If the loadpath is not specified, then it defaults to the current working directory.
Second, the schema has been pulled out into a separate file. The first line of that schema template is now marked as a declaration template. Such a template can only include type, variable, and function declarations. Such a template will be included at most once when building an object; all inclusions after the first will be ignored. This allows many different template to reference type (and function) declarations that they use without having to worry about accidentally redefining them.
Third, the schema template name is common/schema and must be located in a file called common/schema.pan; that is, it must be in a subdirectory of the current directory called common. This is called namespacing and allows the templates that make up a configuration to be organized into subdirectories. For the few templates that are used here, namespacing is not critical. It is, however, critical for real sites that are likely to have hundreds or thousands of templates. Note that the hierarchy for namespaces is completely independent of the hierarchy used in the configuration schema.
Pulling out common declarations and help maintain coherence between different managed machines and reduce the overall size of the configuration. There are however, more mechanisms to reduce duplication.
Structure Templates¶
Sites usually buy many identical machines in a single purchase, so much of the hardware configuration for those machines is the same. Another mechanism that can be exploited to reuse configuration parameters is a structure template. Such a template defines an dict that is initially independent of the configuration tree itself. For our scenario, let us assume that the four machines have identical RAM, CPU, and disk configurations; the NIC and location information is different for each machine. The following template pulls out the common information into a structure template:
structure template common/machine/ibm-server-model-123;
'ram' = 2048;
'cpu/model' = 'Intel Xeon';
'cpu/speed' = 2.5;
'cpu/arch' = 'x86_64';
'cpu/cores' = 4;
'cpu/number' = 2;
'disk/ide/0/capacity' = 64;
'disk/ide/0/boot' = true;
'disk/ide/0/label' = 'system';
'disk/ide/1/capacity' = 1024;
'disk/ide/1/boot' = false;
'location' = undef;
'nic' = undef;
The structure template is not rooted into the configuration (yet) and hence all of the paths in the assignment statements must be relative; that is, they do not begin with a slash. Also, the location and nic children were set to undef. These are the values that will vary from machine to machine, but we want to ensure that anyone using this template sets those values. If someone uses this template, but forgets to set those values, the compiler will abort the compilation with an error. The undef value may not appear in a final configuration.
How is this used in the machine configuration? The include statement will not work because we must indicate where the configuration should be rooted. The answer is to use an assignment statement along with the create function.
object template nfsserver.example.org;
include 'common/schema';
bind '/' = root;
'/hardware' = create('common/machine/ibm-server-model-123');
'/hardware/location/rack' = 'IBM04';
'/hardware/location/slot' = 25;
'/hardware/nic/0/mac' = '01:23:45:ab:cd:99';
'/hardware/nic/0/pxeboot' = false;
'/hardware/nic/1/mac' = '01:23:45:ab:cd:00';
'/hardware/nic/1/pxeboot' = true;
Finally, the machine configuration contains only values that depend on the machine itself with common values pulled in from shared templates.
Although the example here uses the hardware configuration, in reality it can be used for any subtree that is invariant or nearly-invariant. One can even reuse the same structure template many times in the same object just be creating a new instance and assigning it to a particular part of the tree.
Advanced Features¶
This chapter discusses annotations and logging, two advanced topics that can be used to facilitate the management of sites and better understand a site’s configuration.
Annotations¶
The compiler supports pan language annotations and provides a mechanism for recovering those annotations in a separate XML file. While the compiler permits annotations to occur in nearly any location in a source file, only annotations attached to certain syntactic elements can be recovered. Currently these are those before the template declaration, variable declarations, function declarations, type declarations, and field specifications. Examples of all are in the example file.
@maintainer{
name = Jane Manager
email = jane.manager@example.org
}
@{
Example template that shows off the
annotation features of the compiler.
}
object template mysite/example;
@use{
type = long
default = 1
note = negative values raise an exception
}
variable VALUE ?= 1;
@documentation{
desc = simple addition of two numbers
arg = first number to add
arg = second number to add
}
function ADD = {
ARGV[0] + ARGV[1];
};
type EXTERN = {
'info' ? string
};
@documentation{
Simple definition of a key value pair.
}
type KV_PAIR = extensible {
@{additional information fields}
include EXTERN
@{key for pair as string}
'key' : string
@{value for pair as string}
'value' : string = to_string(2 + 3)
};
bind '/pair' = KV_PAIR;
'/add' = ADD(1, 2);
'/pair/key' = 'KEY';
'/pair/value' = 'VALUE';
The command will produce one output file for each source file, using the directory hierarchy of the source files, not the namespace hierarchy. When processing the files, you must provide both the desired output directory (which must exist) using the --output-dir option, as well as the root file system directory for all of the processed files with the --base-dir option if this is not the current directory. --base-dir option must be adjusted so that the template file paths specified match the template namespaces, as for compiling the templates.
Below is an example:
$ panc-annotations \
--output-dir=annotations \
--base-dir=templates \
mysite/example.pan
This command will produce the following output (with whitespace and indentation added for clarity) in the file example.pan.annotation.xml located in annotations/mysite from template file example.pan located in subdirectory templates/mysite of current directory.
<?xml version="1.0" encoding="UTF-8"?>
<template xmlns="http://quattor.org/pan/annotations"
name="annotations"
type="OBJECT">
<desc>
Example template that shows off the
annotation features of the compiler.
</desc>
<maintainer>
<name>Jane Manager</name>
<email>jane.manager@example.org</email>
</maintainer>
<variable name="VALUE">
<use>
<type>long</type>
<default>1</default>
<note>negative values raise an exception</note>
</use>
</variable>
<function name="ADD">
<documentation>
<desc>simple addition of two numbers</desc>
<arg>first number to add</arg>
<arg>second number to add</arg>
</documentation>
</function>
<type name="EXTERN">
<basetype extensible="no">
<field name="info" required="no">
<basetype name="string" extensible="no"/>
</field>
</basetype>
</type>
<type name="KV_PAIR">
<documentation>
<desc>
Simple definition of a key value pair.
</desc>
</documentation>
<basetype extensible="yes">
<include name="EXTERN"/>
<field name="key" required="yes">
<desc>key for pair as string</desc>
<basetype name="string" extensible="no"/>
</field>
<field name="value" required="yes">
<desc>value for pair as string</desc>
<basetype name="string" extensible="no"/>
</field>
</basetype>
</type>
<basetype name="KV_PAIR" extensible="no"/>
</template>
The output filename includes the full input filename because variants with different suffixes may be present.
Logging¶
It is possible to log various activities of the pan compiler. The types of logging that can be specified are:
- task
- Task logging can be used to extract information about how long the various processing phases last for a particular object template. The build phases one will see in the log file are: execute, defaults, valid1, valid2, xml, and dep. There is also a build stage that combines the execute and defaults stages.
- call
- Call logging allows the full inclusion graph to be reconstructed, including function calls. Each include is logged even if the include would not actually include a file because the included file is a declaration or unique template that has already been included.
- include
- Include logging only logs the inclusion of templates and does not log function calls.
- memory
- Memory logging show the memory usage during template processing. This can be used to see the progression of memory utilization and can be correlated with other activities if other types of logging are enabled.
- all
- Turns all types of logging on.
- none
- Turns all types of logging off.
Note that a log file name must also be specified, otherwise the logging information will not be saved.
The logging information can be used to understand the performance of the compiler and find bottlenecks in the configuration. It can also be used to extract information about the relationships between templates, which are then commonly passed to visualization tasks to allow a better understanding of the configuration. Many examples are included in the distribution as analysis scripts. See the command reference appendix for details.
Build Metadata¶
It is sometimes useful to be able to inject values into the compiled profiles without having to explicitly include a template into each object template. This is particularly appropriate for metadata like build numbers, build times, build machines, etc. This can be achieved by setting the root element that is used to start the build of all profiles. Use the rootElement attribute for ant and the --root-element option for the command line. The value must be a DML expression that evaluates to an dict. For example, this expression
dict('build-metadata', dict('number', 1, 'date', '2012-01-01'))
would result in having the paths /build-metadata/number, /build-metadata/date being set to 1 and 2012-01-01, respectively, in all object templates.
Caution
Values inserted into the profiles in this way are still subject to the usual validation. When inserting values, they must obey the schema you have defined for the profile.
Performance Considerations¶
As configurations become larger, the speed at which the full configuration can be compiled becomes important. The logging features presented in the previous chapter can help identify slow parts of the compilation for you particular configuration. This chapter contains general advice on making the compilation as quick as possible.
Use Specific Paths¶
Whenever possible, use the most specific path and assign a property to that path. The code:
'/path' = dict('a', 1, 'b', 2);
and the block:
'/path/a' = 1;
'/path/b' = 2;
provide identical results, although the second example is easier to read and will be better optimized by the compiler.
Use Escaped Literal Path Syntax¶
In previous versions of the compiler, it was necessary to use a DML block when part of a path needed to be escaped:
'/path' = dict(escape('a/b'), 1);
Newer versions of the compiler provide a literal path syntax in which escaped portions can be written explicitly:
'/path/{a/b}' = 1;
This is both more legible and faster.
Use Built-In Functions¶
Built-in functions are significantly faster than equivalents defined with the pan language. In particular, the functions append and prepend should be used for incrementally building up lists (in preference to push equivalents). There are also functions like to_uppercase and to_lowercase that avoid character by character manipulation of strings.
The list of available built-in functions continues to expand. Check the list of functions with each new release of the compiler.
Invoking the Compiler¶
There are several ways to invoke the compiler, either from the command line, from ant, or from maven. For single, infrequent invocations of the compiler they are roughly equivalent in startup time. However, if the compiler will be invoked frequently it is better to avoid using the command line panc script. The reason for this is that the panc script starts a new JVM each time it is invoked, while the ant and maven invocations can reuse their own JVM. This means that for the panc script, you will pay the startup costs each time it is invoked while for ant or maven you pay it them only once. The startup costs are particularly expensive if you request a large amount of memory and do hundreds of compilations at a time.
Avoid Copying SELF¶
Assignments of SELF to a local variable inside of a code block will cause a deep copy of SELF. In the following code, the local variable copy will contain a complete replica of SELF.
'/path' = {
copy = SELF;
copy;
};
These copies can be time-consuming when SELF is a large resource or when the code is executed frequently. If you manipulate SELF within a code block, always reference SELF directly.
Also be aware that copy and SELF will contain independent copies so that changes to copy to not affect SELF and vice versa. This can lead to bugs that are difficult to find.
Common Idioms¶
As you use the pan configuration, you will discover certain idioms which appear. This chapter describes some of the common idioms so that you can take advantage of them from the start and not need to rediscover them yourself.
Configuration File Templates¶
Although it is much better to create an abstracted schema for service configuration, practically it is often useful to directly embed a configuration file directly in the service configuration. In previous versions of the compiler, the configuration file was often created incrementally in a global variable and then assigned to a path. Something like the following was common:
variable USER = 'smith';
variable QUOTA = 10;
variable CONTENTS = <<EOF;
alpha = 1
beta = 2
EOF
variable CONTENTS = CONTENTS +
'user = ' + USER + "\n";
variable CONTENTS = CONTENTS +
'quota = ' + to_string(QUOTA) + "\n";
'/cfgfile' = CONTENTS;
This can be improved somewhat by using the format function:
variable USER = 'smith';
variable QUOTA = 10;
variable CFG_TEMPLATE = <<EOF;
alpha = 1
beta = 2
user = %s
quota = %d
EOF
'/cfgfile' = format(CFG_TEMPLATE, USER, QUOTA);
This can be further improved by moving the configuration template completely out of the pan language file. For instance, create the file cfg-template.txt:
alpha = 1
beta = 2
user = %s
quota = %d
which can then be used like this:
variable USER = 'smith';
variable QUOTA = 10;
'/cfgfile' = format(file_contents('cfg-template.txt'),
USER, QUOTA);
This is much easier to read and to maintain. It is especially helpful when the included configuration file has a syntax for which an external editor can provide additional help with validation.
Extension Templates¶
Often sets of templates that are intended for reuse will allow the configuration to be extended or modified at particular points by including named templates. For example, the following provides pre-configuration and post-configuration service hooks:
template my_service/config;
include if_exists('my_service/prehook');
# bulk of real service configuration
include if_exists('my_service/posthook');
In both of these cases, the named templates will be included if they can be found on the loadpath. If they are not found, the includes do nothing.
Global Variables as Switches¶
Configuration intended for reuse also tends to expose switches for common configuration options. The idiom looks like the following:
template my_service/config;
variable MY_OPTION ?= false;
'/my_service/config/my_option' =
if (MY_OPTION) {
'some value';
} else {
'some other value';
};
};
In cases where the path simply should not exist if the option is not set, then using a default value of null can be the best option:
template my_service/config;
variable MY_OPTION ?= null;
'/my_service/config/my_option' = MY_OPTION;
In this case, if the variable MY_OPTION is not set to a value before executing this template, the null value will be used and the given path will simply be deleted.
Tri-state Variables¶
Occasionally is is useful to have tri-state variables. The most convenient values to use in this case are true, false, and null. With these values as the three states, you can use is_null to test explicitly for the third state. Using undef for the third value can cause problems because variables are automatically set to undef before executing a variable assignment statement.
Troubleshooting¶
Compilation Problems¶
In a production environment, the number of templates and their complexity will be must greater. Often something goes wrong with the compilation or build resulting in one or more errors appearing on the console (standard error stream). There are four categories of errors:
- Syntax Error
- These include any errors that can be caught during the compilation of a single template. These include lexing, parsing, and syntax errors, but also semantic errors like absolute assignment statements appearing in a structure template that can be caught at compilation time.
- Evaluation Error
- These are the most common; these include any error that happens during the “execution” phase of processing like mathematical errors, primitive type conflicts, and the like. Usually the name of the template and the location where the error occurred will be included in the error message.
- Validation Error
- Validation errors occur during the “validation” phase and indicate that the generated machine profile violates the defined schema. Information about what type specification was violated and the offending path will be included in the error message.
- System Error
- These include low-level problems like problems reading from or writing to the file system.
In general, the errors try to indicate as precisely as possible the problem. Usually the name of the source file as well as the location inside the file (line and column numbers) are indicated. For most evaluation exceptions, a traceback is also provided. Validation errors are the most terse, giving only the element causing the problem and the location of the type definition that has been violated.
There is one further class of errors called “compiler errors”. These indicate an error in the logic of the compiler itself and should be accompanied by a detailed error message and a Java traceback. All compiler errors should be reported as a bug. The bug report should include the template that caused the problem along with the full Java traceback. Hopefully, you will not encounter these errors.
Common Problems¶
Q: “Java Heap Space” warnings appear on console.
If you see messages that refer to “Java Heap Space” while running the compiler, then the java virtual machine does not have enough memory to compile the given templates. You must increase the amount of memory allocated to the java virtual machine when you start the compiler. See the section Running the Compiler for how to specify the VM memory.
Q: The compilation is extremely slow.
If the compilation appears to be slow, check that the compiler is not thrashing because of a limited amount of memory. With the verbose option set, successful compilations will produce a summary like:
2 templates
2/2 compiled, 2/2 xml, 0/0 dep
0 errors, 166 ms, 0 MB/63 MB heap, 12 MB/116 MB nonheap
The last line with gives the maximum amount of heap memory used and the maximum available (the value marked “heap”). If the maximum used is more than about 80% of the maximum available, then you should consider increasing the memory allocated to the java virtual machine. See the section Running the Compiler for how to specify the VM memory.
Q: “missing modifyThread Permission” warnings appear on console.
The java-implementation of the pan language compiler is completely multi-threaded. Internally, it controls several thread pools to handle compilation, execution, and serialization in parallel. At the end of a compilation, the compiler will normally destroy the thread pools that were created. The java security model requires that a program have the “modifyThread” permission to destroy threads. In some environments (notably Eclipse), this permission may not be given to the compiler. If this is the case, then the message “WARNING: missing modifyThread permission” is printed on the standard error. Lacking this permission causes a “thread leak”, but the effects are minor unless an extremely large number of templates are being compiled. If this is the case, then you should either change the configuration to grant this permission to the compiler, or work in an environment that grants it by default (e.g. using ant from the command line).
This problem is fixed if using Java6. If you have several JREs installed, be sure to configure Eclipse to use Java 6. Go to Window → Preferences → Java → Installed JREs. If you don’t see the JRE you want (and you have it installed), use the “Search” button to have eclipse configure the new JRE for you. Make sure you select it after it is found.
Q: Unnecessary rebuild of clusters
It can happen that a cluster is always rebuilt when you run ant, even if there was no change in the dependencies. In this case, you may suspect a Java issue with optimizations enabled by default (JIT). The only workaround is to disable these optimizations by adding the option -Xint to Java VM when running ant. It is achieved differently depending how you started ant:
- From command line: define environment variable ANT_OPTS.
- From Eclipse: right click on build.xml in ant pane, choose Run As... → External Tools... and then click on JRE tab. Be sure to use a separate JRE (if possible Java 6 or later) and add option in the options area.
This problem has been seen on Windows only, with Java 5 and Java 6.
Bug Reporting¶
The pan compiler, like all software, contains bugs. If the problem your experiencing looks to be misbehavior by the compiler, please report the problem. Bug reports can be filed in the in the issues area of GitHub.